EmbodiedMAE
Multi-modal Masked Autoencoder for 3D Plant Phenotyping
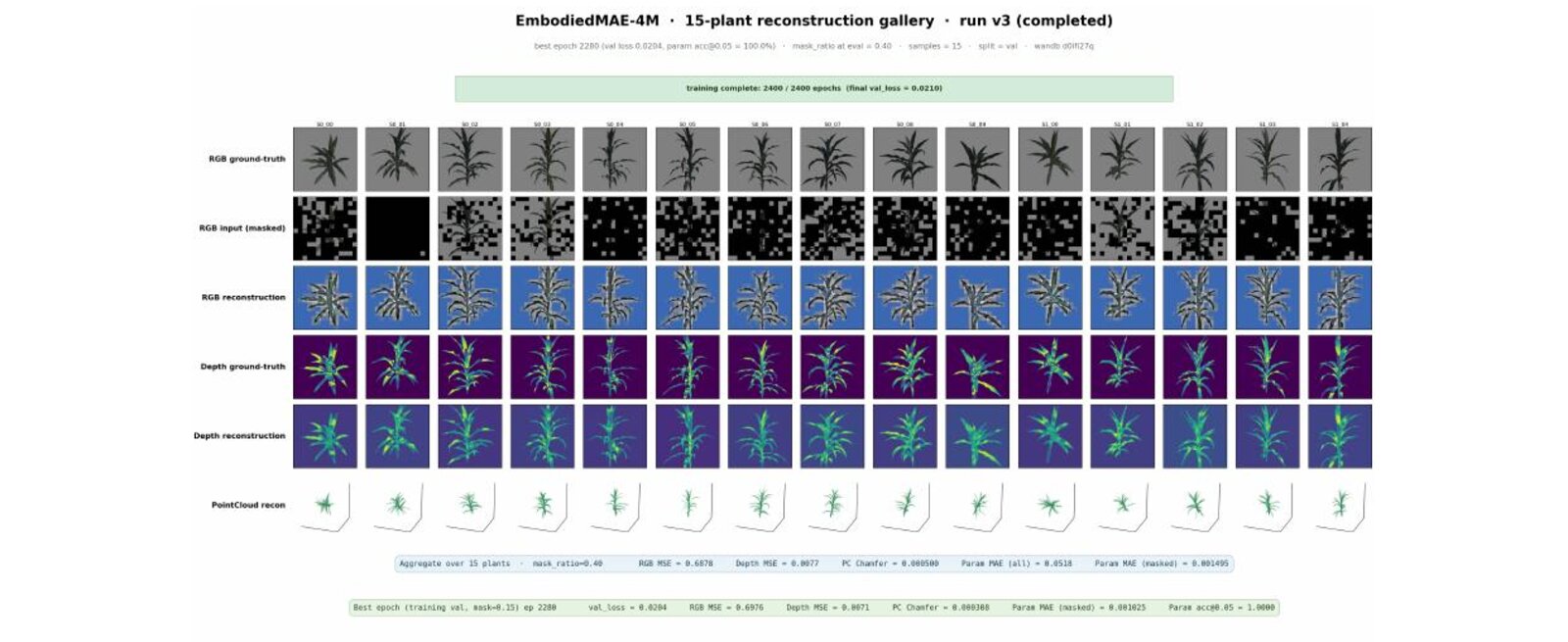
EmbodiedMAE-4M is a four-modality masked autoencoder for 3D reconstruction and phenotyping of Sorghum plants. A single shared ViT-base encoder jointly models RGB images, depth maps, point clouds, and the underlying procedural plant/leaf parameters, learning rich 3D-aware representations without complete supervision.
Motivation
Plant phenotyping — measuring structural traits like plant height, leaf angle, and biomass — is critical for precision agriculture and crop breeding. Traditional methods are manual and slow. EmbodiedMAE automates this via scalable self-supervised learning from procedurally generated synthetic sorghum.
Approach
- Shared encoder: one ViT-base (depth 12, dim 768) encodes tokens from all four modalities — RGB, depth, point cloud (PointNet + FPS), and spline/parameter tokens
- Dirichlet-allocated masking: tokens masked across modalities (mask ratio 0.15, min 0.25 per modality), reconstructed by four modality-specific decoder heads
- Composite loss: RGB / depth MSE + point-cloud Chamfer + Smooth-L1 over plant parameters
- Pre-trained 2400 epochs on 10,000 synthetic plants (~114M params, H200 GPU)
Results
Validation metrics at the best epoch (2280) vs. the final epoch (2400):
| Metric | Best (ep 2280) | Final (ep 2400) |
|---|---|---|
| Val loss (weighted total) | 0.0204 | 0.0210 |
| RGB (per-patch MSE) | 0.0127 | 0.0133 |
| Depth (per-patch MSE) | 0.0046 | 0.0046 |
| Point-cloud Chamfer | 0.000308 | 0.000299 |
| Param MAE (masked tokens) | 0.001025 | 0.001052 |
| Param accuracy @0.05 | 100.0% | 100.0% |
{
"tooltip": { "trigger": "axis" },
"legend": { "data": ["Best (ep 2280)", "Final (ep 2400)"], "top": "2%" },
"grid": { "left": "3%", "right": "4%", "bottom": "3%", "containLabel": true },
"xAxis": { "type": "category", "data": ["Val loss", "RGB MSE", "Depth MSE"] },
"yAxis": { "type": "value", "name": "validation error" },
"series": [
{
"name": "Best (ep 2280)",
"type": "bar",
"data": [0.0204, 0.0127, 0.0046],
"itemStyle": { "color": "#4f8ef7", "borderRadius": [4, 4, 0, 0] }
},
{
"name": "Final (ep 2400)",
"type": "bar",
"data": [0.021, 0.0133, 0.0046],
"itemStyle": { "color": "#7fcfe8", "borderRadius": [4, 4, 0, 0] }
}
]
}
Reconstruction Gallery
Status
Active development. Part of PhD research at SCSLab, Iowa State University.