Swin-TESTR
Multi-lingual pre-training for domain-adaptive text spotting
Swin-TESTR investigates domain-adaptive scene text spotting — leveraging multi-lingual datasets for pre-training to enhance text spotting across languages, synth-to-real, and document domains. Published at WACV 2024.
Problem
Existing approaches pretrain on natural-scene text without exploiting the intermediate feature representations shared between multiple domains.
Approach
- A transformer baseline (Swin-TESTR) for both regular and arbitrary-shaped text spotting
- Exploits intermediate representations across domains to improve transfer
- Exhaustive evaluation demonstrating gains in accuracy and efficiency across multiple text-spotting benchmarks
Results
Detection H-mean across standard benchmarks plus low-resource Vietnamese (VinText):
| Method | TotalText | CTW1500 | ICDAR-15 | IC15 E2E (S) |
|---|---|---|---|---|
| ABCNet v2 | 87.0 | 84.7 | 88.1 | 82.7 |
| TESTR | 86.90 | 86.3 | 90.0 | 85.2 |
| Swin-TESTR | 87.95 | 88.19 | 90.13 | 86.63 |
{
"tooltip": { "trigger": "axis", "formatter": "{b}: {c}%" },
"grid": { "left": "3%", "right": "4%", "bottom": "3%", "containLabel": true },
"xAxis": { "type": "category", "data": ["TotalText", "CTW1500", "ICDAR-15", "VinText"] },
"yAxis": { "type": "value", "name": "detection H-mean (%)", "max": 100 },
"series": [
{
"name": "Swin-TESTR",
"type": "bar",
"data": [87.95, 88.19, 90.13, 73.2],
"barMaxWidth": 55,
"itemStyle": { "color": "#4f8ef7", "borderRadius": [4, 4, 0, 0] },
"label": { "show": true, "position": "top" }
}
]
}
Qualitative Results
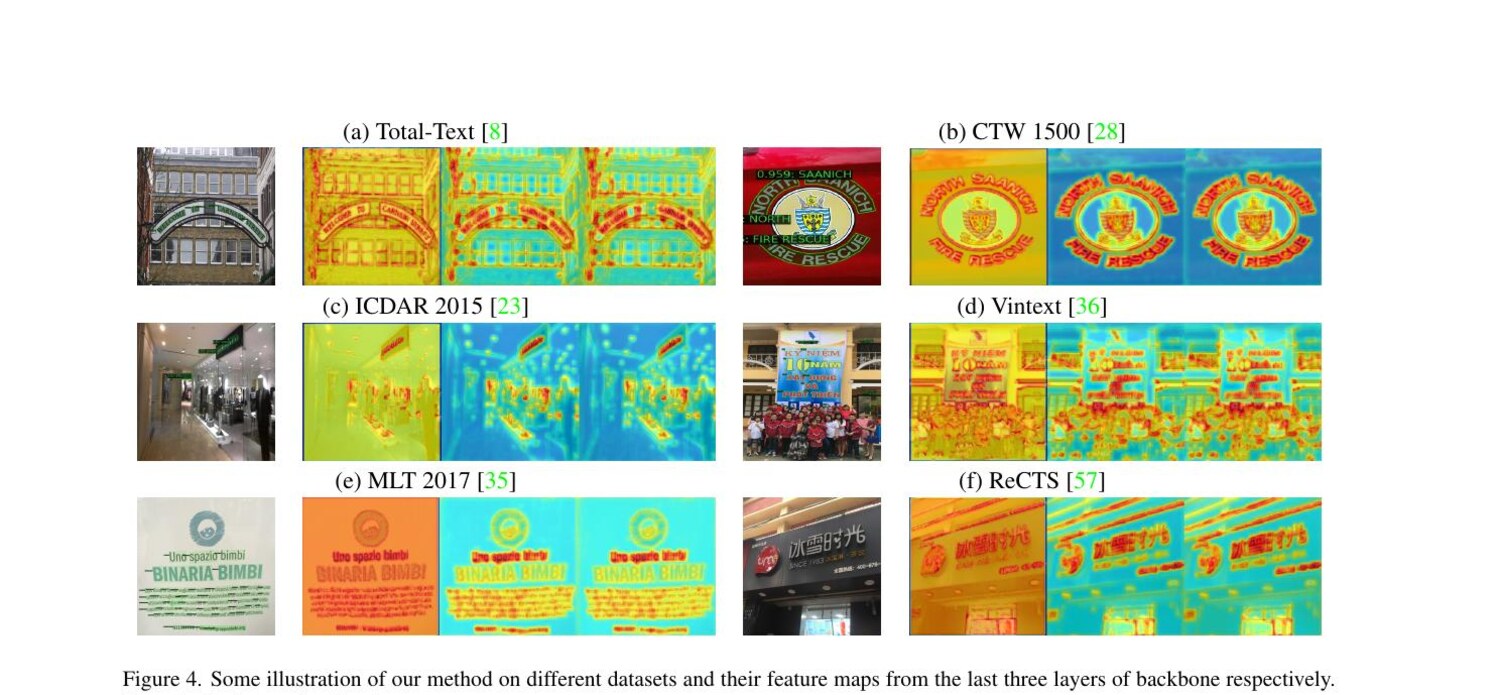
Publication
Das, A., Biswas, S., Banerjee, A., Lladós, J., Pal, U., Bhattacharya, S. Harnessing the Power of Multi-Lingual Datasets for Pre-training: Towards Enhancing Text Spotting Performance. WACV 2024. (arXiv:2310.00917)
Work done at CVPRU, Indian Statistical Institute Kolkata.